Never Miss an RFP
Get the best-fit state and local government procurement opportunities delivered to your inbox. Say goodbye to missed deals and hello to more wins!

Know Before RFPs Come Out
Set email alerts to know about RFPs before they hit the street. Sources include RFIs, RFQs, and contracts coming up for rebid. Use criteria like keywords, geography, population size, and specific agencies to see only the pre-RFP alerts that matter to you.
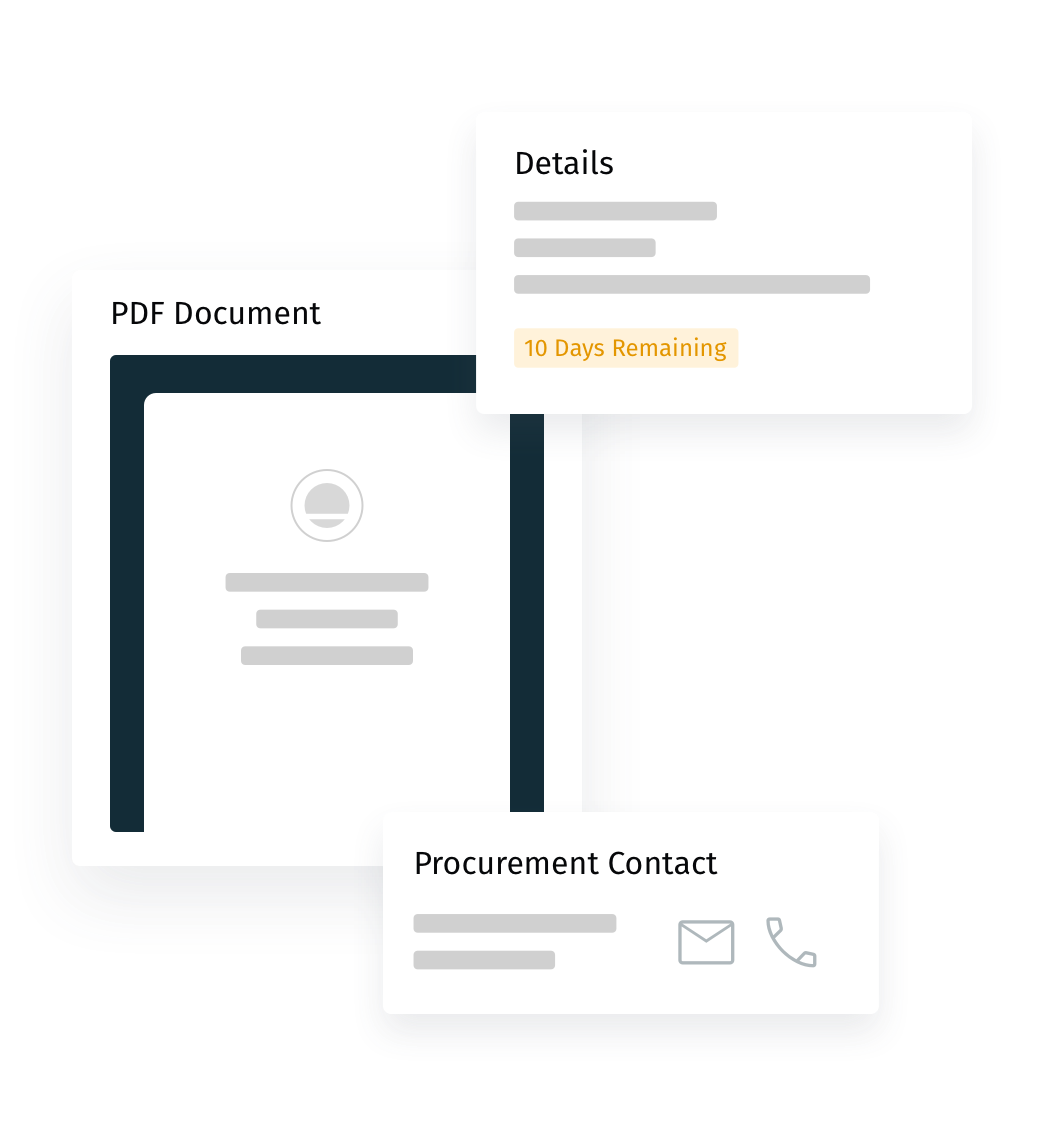
Quickly Assess RFPs
All of the information you need to decide whether or not to respond to an RFP in one place. Details include key dates, description, purchasing contact, and a PDF of the RFP.
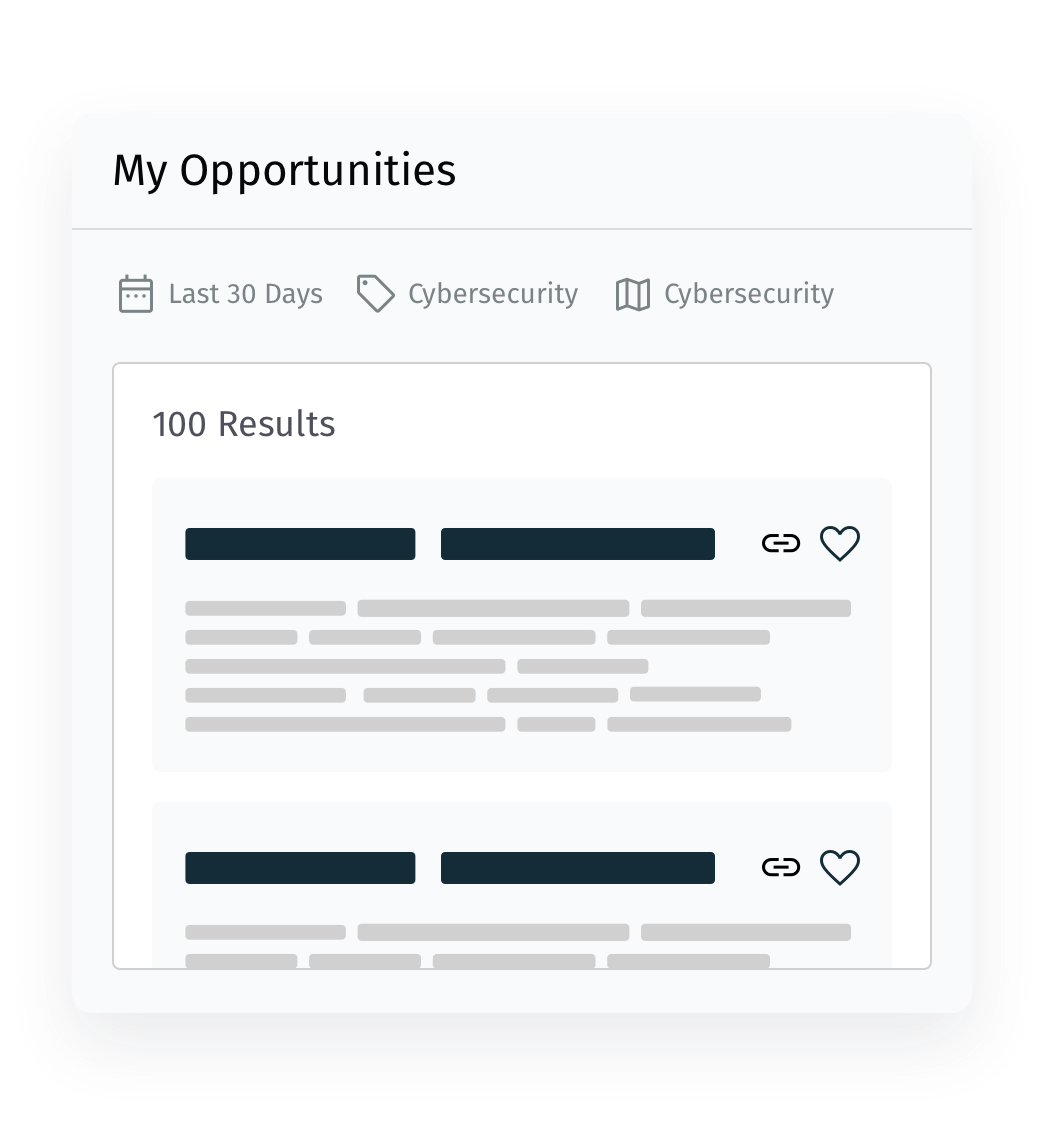
All the RFPs that Matter
Dial-in your email procurement alerts with criteria that include keywords, geography, population size, and specific agencies. Only see the RFPs that interest you with MarketEdge.
When Data Speaks, Are You Listening?
Learn how active data can uncover new in-market opportunities to build a more powerful, sustainable pipeline.
Request Demo